中文不乱、截图逼真,OpenAI凌晨发布的GPT-Image-2直接封神!设计师这回真哭了
如果你用AI画过图,大概率明白AI是很难做到一步到位的。
图片里有中文,那么缺字漏字完全是常态,字要么缺笔要么乱飞,让它做个界面截图,总有一种说不出来的假......这些问题,在很长一段时间里几乎是无解的。
现在,这一整套问题,被GPT-Image-2推翻了。
4月22日凌晨,OpenAI直接把GPT-Image-2推给所有用户,没有发布会,也没有复杂铺垫,但AI社区瞬间被点燃,所有用了GPT-Image-2的人都被震撼了。
划重点!文末藏着惊喜福利,
扫码就能免费体验 GPT-Image-2,千万别错过!
文字终于稳定了!
AI画图最大的痛点,从来不是画不好,而是写不好字。
你让它做一张带文案的海报,出来的文字基本不可用,尤其是中文,复杂结构一多,基本必崩。
现在,GPT-Image-2把这个问题直接解决了。

官方测试中,文字渲染准确率接近99%,落到实际使用,就是你可以直接生成完整排版的内容图——标题、正文、注释、信息块,全部在一张图里完成,而且对齐、间距、层级都正常。

更关键的是多语言支持明显增强,中文、日文、韩文这类字符,不再是短板。
以前的流程是:AI出图 + 手动改字。
现在很多场景变成:一步直接出成品。
界面生成能力增强
以前的AI可以做“像某个平台的界面”,但只要稍微细看,就会发现结构不对,细节也不对。
但现在GPT-Image-2的情况是,你让它生成一个内容平台页面,出来的不只是一个外观相似的画面,而是包括头像位置、互动区域、信息层级在内的完整结构。

你看,每个元素都在它该在的位置!
没有一个错字、交互弹窗也完全正确,贴心到连弹幕内容都是主题相关的,精致到让人几乎找不出破绽。
提示词大幅简化
以前想要好结果,提示词需要写得非常细致,甚至要像写说明书一样,把每个细节拆开描述。
而GPT-Image-2,只要说清楚想要什么,模型会自动补齐很多内容,比如排版方式、视觉层级、细节处理。
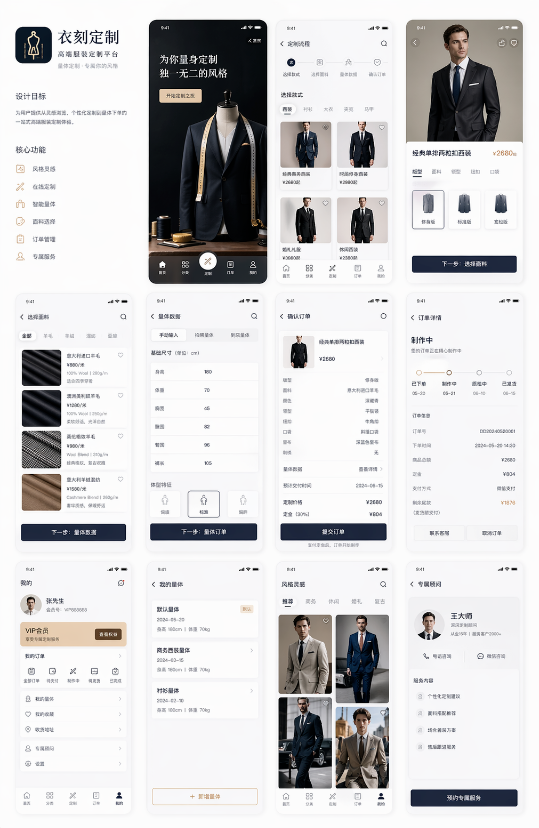
提示词:设计一套完整的服装定制App的产品UI图
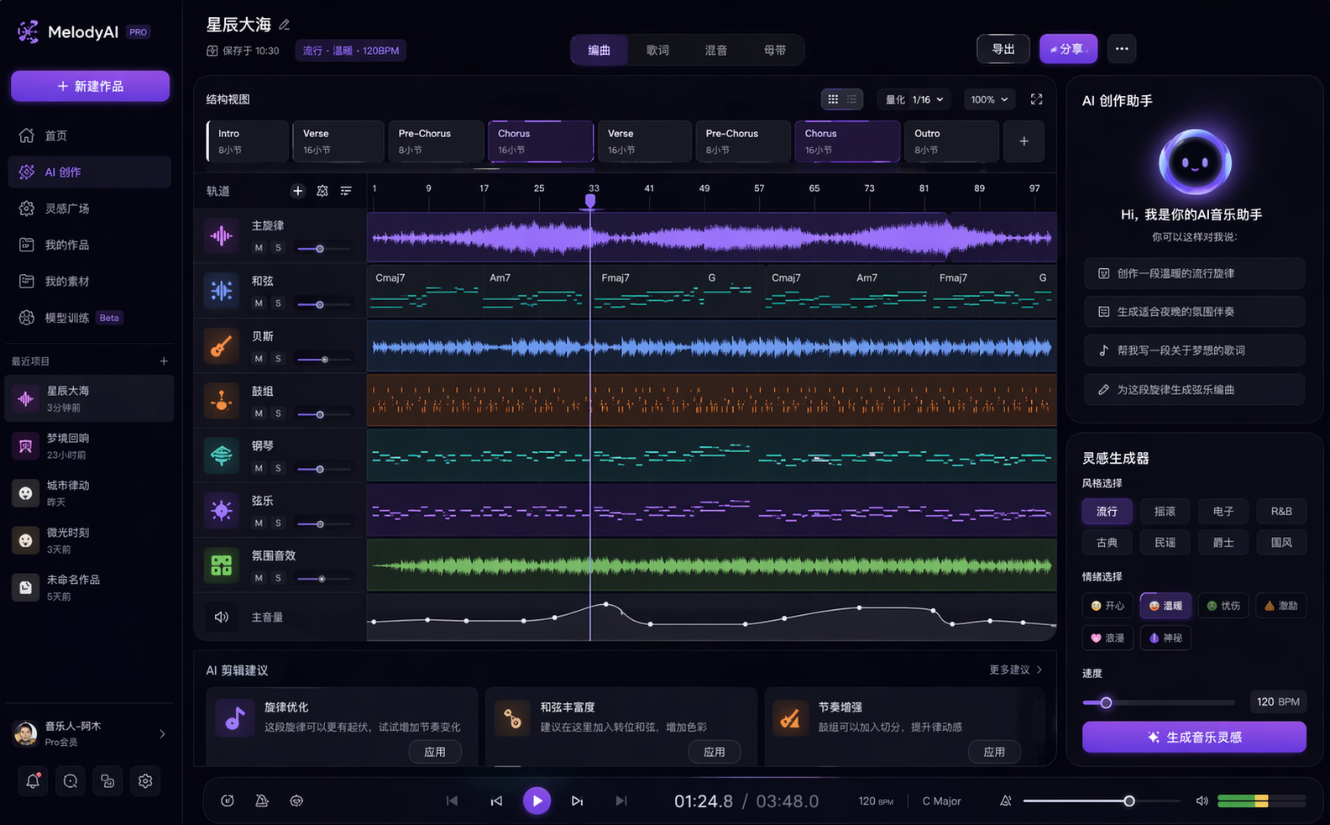
提示词:设计一套完整的AI音乐创作App的产品UI图
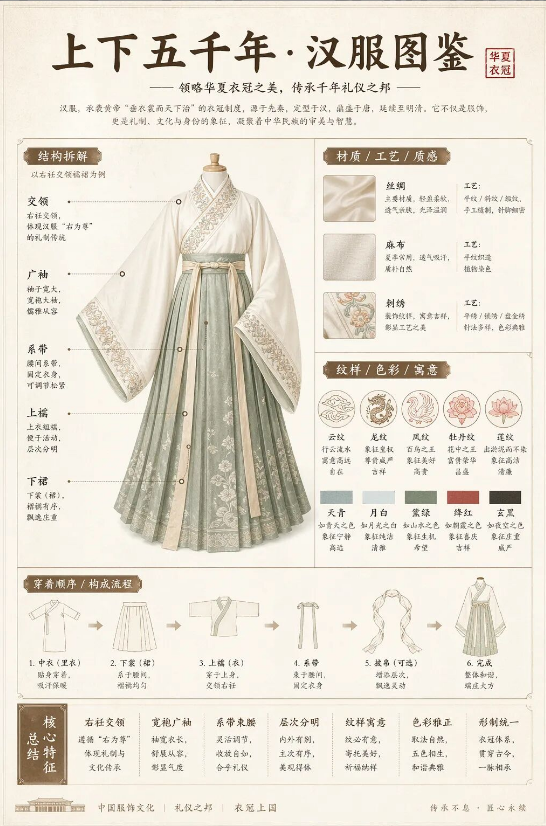
提示词:设计一张汉服结构拆解图鉴
怎么样?
是不是强大到让人起鸡皮疙瘩?
为什么这次差距这么大?
关键原因,不在表面效果,而在底层逻辑。
过去的图像模型是在根据描述拼一个结果,本质上是在做相似度匹配,而GPT-Image-2,更接近先理解现实结构,再去生成画面。
这里有几个重要变化:
1.模型结构是独立设计的,不再依赖语言模型做中间转换,减少信息损耗,生成更直接。
2.训练内容覆盖大量真实世界数据,不只是图片,还包括界面规范、排版体系、视觉规则等。
3.文字处理被单独强化,建立了更精确的映射机制,复杂字符也能稳定输出。
这些改变叠加起来,才让结果从“像”变成“接近真实”。
当这些能力组合在一起,影响就不只是“更好用”那么简单了。以前AI生图主要用在前期,比如找灵感、做草稿,现在完全足以进入实际生产。

内容团队可以直接生成带完整信息的配图,电商可以批量做商品视觉,小团队也能完成过去需要设计资源的工作。
同时,这套能力会通过API开放,意味着它可以被嵌入到各种产品中,变成更基础的一层能力。
最后
这次GPT-Image-2带来的,不只是一次升级。
它把AI生图从一个“能用的工具”,推进到了“可以直接产出结果”的阶段。
接下来,重点可能不再是画得像不像,而是看这些能力,未来将如何进入真实世界的工作流程里。
重磅消息!
现在扫码,在青虎AI体验GPT-Image-2!
限时免费开放!
(点击图片,进入青虎AI小程序)
想亲自体验这波变化,
可以直接上手试试。
很多以前做不到的效果,
现在基本一句话就能跑出来!